
yeon_vision_
[2023-1 졸업프로젝트] FaceRecognition & YOLOv5 본문
2022년 9월부터 시작해
1년간 진행했던
컴퓨터공학과 캡스톤디자인프로젝트가 끝을 보이고 있다.
23년 1월쯤 주제를 변경하게 되어
사실상 해당 주제 개발을 한지는 4개월정도밖에 안되지만 말이다.
하나의 포스트에는 담을 수 없는 수많은 시행착오를 겪었지만
지금은 사정상 하나의 포스트에 담아보고자 한다.
#얼굴인식 #MTCNN #ArcFace
#YOLOv5 #SceneClassification #ObjectDetection
#GoogleColab #TecentCloud_VirtualMachine
✅팀원은 누구인가?
이화여자대학교 컴퓨터공학과 20학번인 임연우, 이정현, 유효주로
1년간 11팀으로서 함께 기획·개발하였다.
✅어떤 서비스인가?
AfterTrip은
여행 후 그룹별 사진 공유의 불편함을 해결하기 위해
얼굴인식AI와 객체인식AI를 이용해 폴더를 분류하는
사진 공유용 모바일 웹이다.
[서비스 소개 & 유사 서비스]
AfterTrip은 ‘여행 후 그룹별 사진 공유’ 서비스로, 기록보다는 공유에 초점을 두고 있습니다.
따라서 유사 서비스로는 카카오톡, airdrop 이 있으며 카카오톡은 30장마다 끊어 전송해야하고,
사진 공유가 아닌 메신저 기능에 초점을 두고 있다는 단점이,
airdrop은 아이폰끼리만 전송 가능하다는 단점이 있습니다.
이에 비해 저희 서비스는 모바일 웹서비스로 모든 기기에서 사용가능하며,
여러장을 한번에 업로드 가능하고, 얼굴별 객체별로 자동 분류하고, chat GPT를 이용한 검색도 가능해
‘그룹별 사진 공유’에 최적화된 서비스라는 장점이 있습니다.
아이폰 앨범에서 이미 폴더분류, 사진검색 기능을 제공합니다.
하지만 아이폰앨범, 갤럭시앨범, 구글포토에서는 그룹별로 공유앨범을 생성할 수는 있으나
그 공유앨범안에서의 검색, 분류 등을 제공하지 않습니다.
또한 구글 포토는 갤러리 전체 사진을 백업해야 얼굴별분류 기능을 이용할 수 있습니다.
즉 여행사진만을 대상으로 자동폴더분류를 진행할 수 없습니다.
그렇기에 여행 후 쉽고 빠른 사진 공유 서비스로 AfterTrip을 추천드립니다.
[기술구현을 위한 흐름 설명]
유저가 프론트 화면을 통해 로그인한 후 유저끼리 그룹 초대를 해 그룹을 생성하고,사진을 업로드하면,
백엔드에서 사진을 DB에 저장하고 해당 그룹구성원만 볼 수 있게 하고,
AI를 이용해 사진마다,
얼굴인식AI를 통해 폴더분류를 하여 몇번 사람인지 인물tag를 붙이고,
객체인식AI를 통해 객체tag (바다, 산, 개, 음식, 사람...)를 붙이면,
해당 인물tag와 객체tag를 DB에 저장해두고 폴더분류에 이용하고
그 결과를 프론트 화면에서 앨범 형식으로 볼 수 있다.
그리고 그 tag값과 기타 메타정보들만 ChatGPT에게 넘겨서 (보안 문제로 이미지 원본은 넘기지 않는다)
유저의 질문에 ChatGPT가 사진 index를 대답하면 유저는 프론트에서 해당 사진을 볼 수 있다.
✅나는 무엇을 담당했는가?

Backend는 Django와 AWS EC2 instance, S3 Bucket을,
Frontend는 React를 이용하였다.
나는 AI를 담당하였으며
얼굴인식AI에는 MTCNN모델과 Arcface loss function을,
객체인식AI에는 YOLOv5를 이용해 classification과 obejct detection을 진행하였다.
(총 3명의 팀원, 각각 AI, BE, FE 담당)
✅ AI 공통
#️⃣ [개발환경] 구글 코랩 vs 로컬 vs 텐센트 클라우드
구글 코랩 & Ubuntu 가상머신 & 로컬
아래 3가지 개발환경을 이용해 개발하였다.
◾ 1. 구글 코랩
ipynb 파일로 실행이 간편하고
torch, tensorflow, cuda 등 필요한 패키지가 이미 설치되어있으므로 간편하다.
아래 코드를 이용한 구글드라이브와의 mount하여 개발하면 좋다.
from google.colab import drive
drive.mount('/content/drive')
또 다른 tip은 구글드라이브의 데스크탑용 드라이브를 이용해 로컬과 연동하면
파이참으로 코드를 열 수도 있고 여러모로 편하다.
하드웨어가속기를 GPU로 선택하면 GPU도 이용할 수 있어서 좋다.
◾ 2. Ubuntu 가상머신
학교에서 제공해준 Tecent Cloud 의 가상머신을 이용했다.
Teslor T4 GPU가 있는 머신이다.


◾ 3. 로컬
팀원전원이 window 노트북으로 개발을 진행 중이다.
gpu가 있는 데스크탑이 없어서 AI모델을 로컬로 train할 수는 없었다.
Ubuntu 가상머신 서버 원격 접속 방법
◾방법1. 텐센트에서 콘솔로 열기
자꾸 connection이 끊겨서 불편했다.
◾방법2. PuTTY로 ssh 연결
파일 편집할때 불편했다.
◾방법3. vscode로 ssh 연결 (!추천!)
vscode에서 'Remote Development' extension을 설치하고
ssh 연결을 하면 개발하기 편하다.
개발 환경 & 배포 환경을 맞출 것
나는 구글 코랩에서 train을 완료 하고
동일한 코드를 BE담당팀원의 로컬 윈도우 노트북으로 실행하려 했더니 안되는 경우가 있었다.
( path 문제 : 윈도우 path 구분자는 백슬래쉬\, 리눅스 계열 path 구분자는 슬래쉬 / )
( yolo모델 model load 문제 : module is not callable 에러가 났다 )
모델 train 환경 : 리눅스
로컬 : 윈도우
배포 서버 : 리눅스
이므로 배포 서버에서는 정상작동 되었다.
계속 개발을 해야하므로 로컬과 배포서버에서 모두 코드가 돌아가야만 한다.
따라서 개발 환경과 배포 환경을 맞춰주는 일은 매우 중요하다.
개발 환경에서 docker를 통해 환경을 맞춰서 개발하도록 하자!
#️⃣ [기술적 성취] 모듈화해서 여러 파일간의 import 시 path 자동 설정
import sys
from pathlib import Path
# 현재 파일의 path를 기반으로, 해당 파일이 들어있는 폴더의 path를 추출 = BASE_PATH
FILE = Path(__file__).resolve()
BASE_PATH = FILE.parents[0]
# PATH에 해당 BASE_PATH를 추가
if str(BASE_PATH) not in sys.path:
sys.path.append(str(BASE_PATH))
# 그 결과
# BASE_PATH에 있는 파일들은
# 절대경로를 적어줄 필요 없이 아래처럼 간단하게 import 가능하다.
from face_crop import face_crop
from get_embeddings import get_embeddings
from face_grouping import face_grouping
이렇게 해당 파일의 위치를 기준으로 폴더PATH를 추출해
sys.path에 추가해두면
구글코랩, 내 로컬, BE 개발자 로컬, 텐센트 클라우드 서버, 도커 이미지 내부... 등 다양한 곳에서
정상적으로 실행되야하는 경우
path를 수동으로 바꿔주지 않아도 돼서 편리하다.
#️⃣ [개선할 점]
Image Hashing 기법을 이용해
동일한 사진은 서버에 한번만 올라가게 하는 기능을 추가하였으면 더욱 좋았을 것 같다.
시간상 못했으나 추가할 예정이다.
image1 -> hash function f(x) -> hashcode1
image2 -> hash function f(x) -> hashcode2
image3 -> hash function f(x) -> hashcode1
***(images2 : image1과 다름. 따라서 image1과 해쉬코드 다름)
***(images3 : image1과 동일한 이미지이나 다른 파일명으로 재업로드됨. 따라서 image1과 해쉬코드 동일)
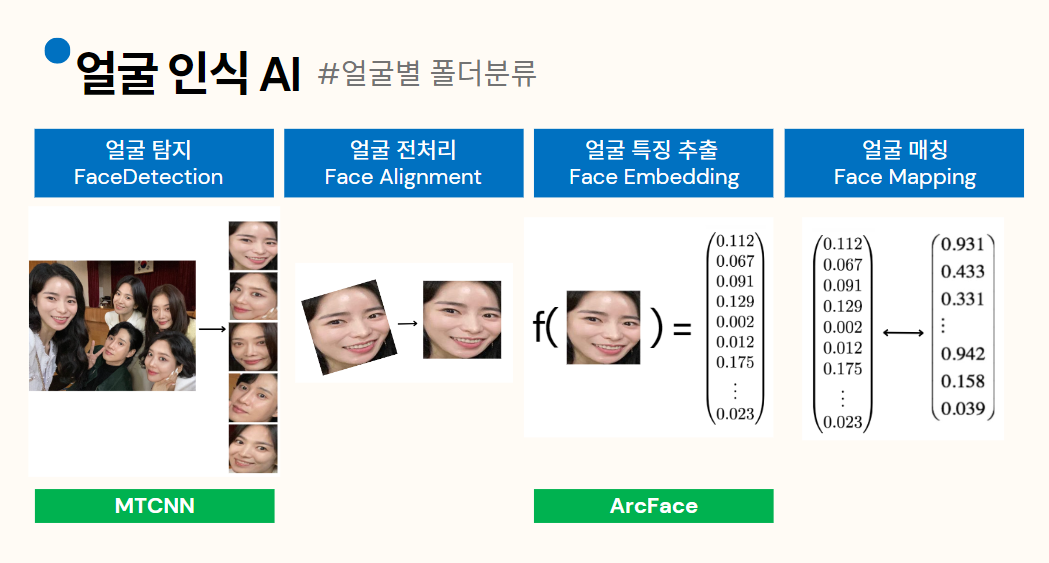
✅ 1. 얼굴인식 AI
#️⃣ [기술적 성취] 얼굴인식으로 동일인물끼리 사진앨범 묶기
초반에 기술 검증을 할 당시
얼굴인식 AI, 얼굴탐지 AI 모델 등은 굉장히 많기에 쉽게 오픈소스를 찾을 수 있다 생각했다.
하지만 얼굴이 어딘지 인식하는 모델과 코드는 많아도,
한 사진에 대해 모든 얼굴을 인식하고,
그 얼굴을 embedding해서 유사도를 계산한 후,
유사한 얼굴끼리 grouping하여 앨범으로 묶어주는 오픈소스는 쉽게 찾을 수 없었다.
결국에는 수많은 검색과
기술검증을 위한 코드를 통해
한 사진에 대해 모든 얼굴을 인식 -> mtcnn모델
그 얼굴들을 embedding하기 -> arcface loss func
embedding간의 유사도 계산 -> cosine similarity
유사한 얼굴끼리 grouping -> 유사도가 threshold 이상이면 동일 그룹으로 grouping하는 알고리즘 고안
으로 구현하기로 확정하고 개발에 성공하게 되었다.
개발 초반에는 기존의 저명한 모델만 잘 이용한다면
구글포토, 아이폰앨범과 유사한 성능을 낼 수 있다고 기대하였으나
우선 아이폰은 핸드폰 내부의 neural processing unit NPU를 이용해 서버에 보내지않고 핸드폰 내에서 face recognition하는 것 같았고
구글포토 등은 관련 정보를 찾기 어려웠고 당연히 오픈소스코드는 구하지 못하였으며
우리가 사용할 수 있는 서버도 gpu서버한대이므로 user의 요청량을 감당하기는 어려워 속도 및 성능이 그에 미치지는 못하였다.
자체 AI 모델을 개발하기에는 주어진 시간도, 자원도, 내가 아는 지식도 충분치 못하였다...
따라서 기대보다는 좋지 못한 성능이지만 여러 모델을 합쳐가며 개발하면서 성장하였고,
개발도 완성되었고,
해당 모델들의 기술을 이해하며 개발하였고,
현재 우리의 전체 파이프라인에 기술적으로 무엇이 부족한지 깨달았기에 의미가 있다고 생각한다.
#️⃣ [Step1. face detection & crop] MTCNN 모델
◾ MTCNN 이란?
CNN을 이용해 얼굴 검출 정확도를 95% 수준까지 끌어올렸으며
약 1300회 인용된 논문의 Face Detection AI 모델이다.

본 논문 저자에 의하면
얼굴을 검출해내는 Face Detection
눈, 코, 입의 좌표를 알아내는 Face Alignment
얼굴 위치를 나타내는 박스의 위치를 세밀하게 조절해주는 bounding box regression
3가지의 일을 동시에 학습시키면 시너지가 나며 학습이 간단해질 것이라 주장한다.
저자들은 이러한 3가지 테스크를 학습한 P-net, R-net, O-net이라는 세 CNN을 차례로 통과하는 Cascade 모델을 제안한다.



해당 모델의 단점은
초반에 이미지 피라미드를 생성하고 이를 12x12 크기의 윈도우로 CNN inference하는 부분이 bottle neck이 되어
이미지의 해상도가 커질 수록 성능저하(즉 속도 느려짐)가 발생한다.
그런데 요새 핸드폰으로 촬영하는 사진이 해상도가 굉장히 크므로 우리 서비스에서 이용 시 느린 속도를 보여준다.
(이미지 한장에 1~2초 소요, cpu이용)
하지만 다른 적합한 모델을 찾지 못하여 현재는 MTCNN모델을 적용 중이다.
◾ 이미지 url을 pixel으로 변환
user가 올린 이미지는 BE에서 AWS s3 버켓에 저장되어 url이 생성되고
해당 url이 face_recognition_ai 모델의 input이다.
따라서 해당 url을 아래과정처럼 request를 통해 이미지를 받아오고
해당 이미지를 RGB로 convert한 후
np array로 변형해준다.
for idx, image in enumerate(images):
# s3에서 생성된 url을 request&response로 받아서 img로 넘기기
res = request.urlopen(image["url"]).read()
img = Image.open(BytesIO(res))
img = img.convert('RGB')
pixels = np.asarray(img)
# face detect 얼굴 탐지
images, file_no_face = face_crop(idx, pixels, images, crop_folder)
그렇게 변환된 pixel을 MTCNN모델의 input으로 넣어
face detect한 후 detect한 face부분을
112x112 사이즈로 crop하여 폴더에 저장한다.
detector = MTCNN()
results = detector.detect_faces(pixels)#️⃣ [Step2. embedding] 얼굴 loss fuction (손실 함수)의 최근 연구 동향 파악
참고 블로그 : https://tech.kakaoenterprise.com/63
얼굴 인식을 학습하기 위한 손실 함수는
소프트맥스 손실 함수(softmax loss function),
거리 기반 손실 함수(distance-based loss function),
앵귤러 마진 기반 손실 함수(angular margin based loss function) 등 크게 세 종류로 나눌 수 있다.



SphereFace에서 CosFace와 ArcFace로 이어지는 근래의 얼굴 인식 연구는 앵귤러 마진을 추가한 소프트맥스 기반 손실 함수를 이용해 서로 다른 인물 간 거리를 충분히 넓히는 방향으로 진행되고 있으며
우리 프로젝트에서는 ArcFace 손실함수를 이용하였다.
#️⃣ [Step2. embedding] data.Dataloader이용으로 속도 개선
AI모델을 돌릴때
( 이미지 1장 -> AI모델 -> 결과 ) * (n번) 보다
( 이미지 n장을 이어붙인 tensor -> AI 모델 -> 결과 ) * (1번) 이 훨씬 빠르다.
행렬 연산 횟수를 생각해보면 당연하다.
따라서 아래와 같이 transforms와 dataloader를 이용해서
폴더에 들어있는 모든 이미지를 한번에 input으로서 불러오는 것이 좋다.
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# define image preprocessing
transform = transforms.Compose([
transforms.Resize(
[int(128 * input_size[0] / 112), int(128 * input_size[0] / 112)],
), # smaller side resized
transforms.CenterCrop([input_size[0], input_size[1]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
],)
# define data loader
dataset = datasets.ImageFolder(data_root, transform)
loader = data.DataLoader(
dataset, batch_size=1, shuffle=False, pin_memory=True, num_workers=0,
)#️⃣ [Step1 & Step2] Step1의 output & Step2의 input 형식 맞춰주기
def face_crop(img_idx, pixels, images, crop_folder, required_size=(112, 112)):def get_embeddings(data_root, model_root, input_size=[112, 112], embedding_size=512):Step1의 output size를 required_size=(112, 112)로 지정하였으면
Step2의 input size를 input_size=(112, 112)로 맞춰주는 것을 잊지말자
#️⃣ [Step1 & Step2] crop_image에서 original_image 찾아가기
이 과정에서 개발 고민이 생겼었다.
전체 파이프라인이 1. FaceDetection(MTCNN) -> 2. FaceEmbedding(ArcFace) -> 3. CosineSimiliarty -> 4. Grouping 인데
1단계에서는 사진 한장마다 MTCNN모델을 run시키고,
2단계에서는 잘린 얼굴 사진이 들어있는 폴더를 dataset loader를 이용해 한번에 input으로 받는다.
//이 방법이 불가능하고,
for _, image in enumerate(images) : //이미지 하나마다
//1단게 수행
//2단계 수행
//아래처럼 실행.
//[1단계 수행]
for _, image in enumerate(images) :
//하나의 image에 대해 detect되는 모든 얼굴영역을 잘라서 crop folder에 저장
//[2단계 수행]
//crop 폴더에 들어있는 모든 이미지에 대해 embedding
2단계_함수(crop_folder_path)그래서 우리는 crop된 얼굴이미지와 그 path만 가지고
original 이미지를 찾아가야하는 문제가 발생한다.
(이미지명이 original 은 n.jpg, crop은 n_m.jpg 형식인데
1단계에서는 for 문으로 불러왔는데 순서가 1 2 3 ...10 11 12... 이런식
2단계에서는 dataloader로 불러왔는데 순서가 1 10 11 12 2 3 .... 이런식이라
단순히 index만으로는 sync를 맞추기 힘들었다)
(방법1) (사용안함) 파이썬 딕셔너리 이용
crop_path를 key로
original_path를 value로 저장해두고
dict[crop_path] 를 하면 original_path 값을 알 수 있다.
(방법2) (사용함) crop path를 문자열 parsing해서 original path를 찾아간다.
original_path = 0.jpg
crop_path = 0_1.jpg -> original_img_idx = 0
crop_path = 0_2.jpg -> original_img_idx = 0
...
crop_path = 0_5.jpg -> original_img_idx = 0
original_images_filename = os.path.split(crop_path)[1] # 전체 경로에서 file name만 parsing
original_images_filename = original_images_filename.split('.')[0] # 1_3.jpg에서 "1_3" parsing
original_images_idx = int(original_images_filename.split('_')[0]) # 1_3에서 "1" parsing해서 int로 변환
#️⃣ [Step2. embedding] t-SNE 를 이용한 분포 결과 확인
◾ cf) t-분포

◾ t-SNE란?

t-distriduted stochastic neighbor embeding (t-SNE)는
높은 차원의 복잡한 데이터를 2차원에 차원 축소하는 방법이다.
낮은 차원 공간의 시각화에 주로 사용하며
차원 축소 시에는 비슷한 구조끼리 데이터를 정리한 상태이므로 데이터 구조를 이해하는데 도움을 준다.
◾ t-SNE를 이용한 face embedding 결과 시각화
각 얼굴에 대한 embedding 벡터들이 들어있는 list인 embeddings를
t-sne를 통해 분포 결과를 확인해보면 다음과 같다.

#️⃣ [Step3. cosine-similarity] face embedding의 유사도 계산
(얼굴1에 대한 embedding vector)과 (다른 얼굴에 대한 embedding vector)를
이중 for문을 돌며 cosine similarity를 구하면 속도가 느려진다.
O(n^2) (n은 user가 업로드한 사진에서 추출한 전체 얼굴의 개수)
코사인 유사도의 수식을 보면 다음과 같이 단순 벡터내적 연산이다.

따라서 (모들 얼굴에 대한 embedding vector)가 들어있는 list인 embeddings vector를
그것을 transpose한 vector와 dot product하면
한번의 내적 연산으로 cosine similarity가 들은 n*n짜리 list를 얻을 수 있다.
cosine_similaritys = np.dot(embeddings, embeddings.T)
cosine_similaritys = cosine_similaritys.clip(min=0, max=1)ex) print(cosine_similarity[n][m]) -> 0.73452
#️⃣ [Step4. grouping ]
# pseduo code
for face_idx, face in enumerate(faces) : # 어떤 한 사진에 대해
# Case 1 : 기존 그룹 탐색
# 각 그룹마다
# 그 그룹에 들어있는 사진마다
# cosine_similarity가 threshold보다 높다면, 그 그룹에 추가
# Case2 2 : 위의 기존그룹탐색에서 어떤 그룹에도 들어가지 못했다면, 새로운 그룹 생성 후 거기에 추가 # face1 : 비교 기준이 되는 이미지
# face2 : 지금 그룹을 정해주고 싶은 이미지
groups = []
group_idx_list = []
for face2_idx, face2 in enumerate(faces): # 해당 얼굴에 대해
is_already_in_group = False
# Case1 : 기존 그룹 탐색
for group_idx, group in enumerate(groups): # 각 그룹마다
for i, face1_idx in enumerate(group["face2_idx_list"]): # 그 그룹에 들어있는 얼굴마다
cosine_similarity = cosine_similaritys[face1_idx][face2_idx]
if (not is_already_in_group and cosine_similarity > cos_similarity_threshold):
crop_path = face2["crop_path"]
original_images_filename = os.path.split(crop_path)[1] # 전체 경로에서 file name만 parsing
original_images_filename = original_images_filename.split('.')[0] # 1_3.jpg에서 "1_3" parsing
original_images_idx = int(original_images_filename.split('_')[0]) # 1_3에서 "1" parsing
# images에 group idx 넣어주기
if group_idx not in group_idx_list:
group_idx_list.append(group_idx)
if "group_idx" in images[original_images_idx]:
images[original_images_idx]["group_idx"].append(group_idx)
else:
images[original_images_idx]["group_idx"] = [group_idx]
# groups 갱신
group["original_images_idx_list"].append(original_images_idx) # dictionary에서 원래 url idx 찾아넣기
group["crop_path_list"].append(crop_path)
group["face_list"].append(face2["face"])
group["face2_idx_list"].append(face2_idx)
group["face1_idx_list"].append(face1_idx)
group["cosine_similarity_list"].append(cosine_similarity)
is_already_in_group = True
# Case2 : 못 넣었으면 새로운 그룹에 추가
if not is_already_in_group:
crop_path = face2["crop_path"]
original_images_filename = os.path.split(crop_path)[1] # 전체 경로에서 file name만 parsing
original_images_filename = original_images_filename.split('.')[0] # 1_3.jpg에서 "1_3" parsing
original_images_idx = int(original_images_filename.split('_')[0]) # 1_3에서 "1" parsing
# images에 group idx 넣어주기
if len(groups) not in group_idx_list:
group_idx_list.append(len(groups))
if "group_idx" in images[original_images_idx]:
images[original_images_idx]["group_idx"].append(len(groups))
else:
images[original_images_idx]["group_idx"] = [len(groups)]
# groups 갱신
groups.append({
"original_images_idx_list": [original_images_idx],
"crop_path_list": [crop_path],
"face_list": [face2["face"]],
"face2_idx_list": [face2_idx],
"face1_idx_list": [[]],
"cosine_similarity_list": [-1]
})#️⃣ Face Recognition 으로 Face Grouping한 결과



#️⃣ [개선할 점 1] Alignment 추가
현재는 얼굴 탐지 후 얼굴 각도를 조절하지 않는다.
얼굴 각도를 조절하는 alignment단계를 넣는다면 성능이 더욱 좋아질 것이다.
alignment모델도 찾아두었고 테스트도 해보았으나
AfterTrip서비스 개발 시 사용할 수 있는 AI배포용 GPU 서버가 한대뿐이어서 (금액문제로...)
user들의 요청을 감당하려면 AI모델 실행속도가 중요했기에
alignment단계를 생략하고
Face Detection -> (Face Alignment) -> Face Embedding -> Face Grouping 으로 진행하였다.
#️⃣ [개선할 점 2] Embedding 방식 개선.
현재는 Face Detection으로 crop한 얼굴 이미지들의
pixel값의 차이로 그 cosine-similarity를 구한다.
하지만 얼굴의 눈코입 좌표의 차이로 cosine-similarity를 구해야 이론상 맞고 성능이 좋아질 것이다.
#️⃣ 코드 공개
github 링크 : https://github.com/JeongHyoYeon/Capstone-CV-FaceRecognition/tree/main/face_recognition
코드에 대한 설명, 더 많은 결과 이미지, ipynb 파일등은 코드내부의 docstring과 깃허브의 readme 참조 부탁드립니다.

코드는 각 step마다 모듈화를 해두었으며 아래방식으로 실행가능합니다.
# url이 들은 images 정의
'''
images = [
{
"id": 1,
"url": "https://capstone-aftertrip-test.s3.ap-northeast-2.amazonaws.com/6854d9b5-84a1-4532-b312-98429d9d7671"
},
{
"id": 2,
"url": "https://capstone-aftertrip-test.s3.ap-northeast-2.amazonaws.com/140b4477-187a-44e8-aed2-2424fb05ee58"
}
.
.
.
{
"id": 123,
"url": "https://capstone-aftertrip-test.s3.ap-northeast-2.amazonaws.com/9ea78401-31d8-4ebe-8b3a-58632fb8d439"
}
]
'''
# change dir
%cd face_recognition
# run_face_recog 호출
from main import run_face_recog
groups, group_idx_list, images = run_face_recog(images)
✅2. 객체인식 AI
#️⃣ 전체 흐름
개발 초반에는 YOLOv5를 이용한 obejct detection 한번으로 [풍경분류]와 [객체tag붙이기]가
동시에 다 가능할 것이라 생각했다.
하지만 풍경은 배경이고, 객체는 그 앞의 사물이기에 풍경tag, 객체tag를 둘다 붙이려고하면 안되었다.
1차적으로 풍경tag를 붙이기 위해 scene dataset으로 classfication,
2차적으로 객체tag를 붙이기 위해 object detection을 수행하는 것으로 고안하였다.
#️⃣ 데이터셋 구하기
1) scene-classification은 https://universe.roboflow.com/m3-ytsk5/m3finalclass 이 데이터셋을 이용하였다.
8개의 classes
train image 400장
Opencountry
coast
forest
highway
inside_city
mountain
street
tallbuilding
2) object-detection은 COCO dataset을 이용하였다.
80개의 classes
airplane, apple, backpack, banana, baseball bat, baseball glove, bear, bed, bench, bicycle, bird, boat, book, bottle, bowl, broccoli, bus, cake, car, carrot, cat, cell phone, chair, clock, couch, cow, cup, dining table, dog, donut, elephant, fire hydrant, fork, frisbee, giraffe, hair drier, handbag, horse, hot dog, keyboard, kite, knife, laptop, microwave, motorcycle, mouse, orange, oven, parking meter, person, pizza, potted plant, refrigerator, remote, sandwich, scissors, sheep, sink, skateboard, skis, snowboard, spoon, sports ball, stop sign, suitcase, surfboard, teddy bear, tennis racket, tie, toaster, toilet, toothbrush, traffic light, train, truck, tv, umbrella, vase, wine glass, zebra
COCO dataset 이란?
Object Detection 뿐만 아니라 Segmentation, Keypoint Detection등을 위해 제공된 dataset.
ImageNet dataset의 문제점을 해결하기 위해 2014년 제안되었다.
다양한 크기의 물체가 존재하며 높은 비율로 작은 물체들이 존재.
덜 iconic. 즉, 이미지가 특정 카테고리에 명확하게 속해있지 않다.
#️⃣ 일반적인 경우 데이터셋 searching 하는 방법
1. ImageNet, COCO dataset, CIFAR-10 등 알려진 데이터셋 중 적합한게 있나 찾는다.
2. Kaggle 등의 사이트에서 이미 다른 사람이 만들어둔 데이터셋이 있는지 찾는다.
3. Roboflow 등의 사이트에서 다른 사람이 만들어둔 데이터셋을 찾는다.
4. Roboflow 등을 이용해 custom dataset을 만든다. (웹 crawling을 이용해도 좋다)
cf) 정부에서 운영하는 사이트(https://www.data.go.kr/)에서도 양질의 데이터셋이 많다고 한다.
#️⃣ Roboflow
custom dataset을 만들때 좋은 웹사이트이다.
이미지들을 업로드하면 labeling과 split과 agumentation등을 손쉽게 할 수 있다.
box labeling, polygon labeling 등 labeling방법도 다양하다.
cf) 그러나 roboflow에서 다른 사람들이 이미 만들어둔 dataset들은 생각보다 양도 적고 적합한 것을 찾기 어려웠다.



#️⃣ 데이터셋 전처리
AI모델을 dataset load & train 하려면 데이터셋의 구조가 중요하다.
classification의 경우
train_dataset
ㄴ train
ㄴclass1
ㄴimage001
ㄴimage002
...
ㄴclass2
...
ㄴclassN
...
ㄴ valid
ㄴclass2
...
ㄴclassN
...
ㄴ test
ㄴclass2
...
ㄴclassN
...
object detection의 경우
train_dataset
ㄴ train
ㄴimages
ㄴlabels
ㄴ valid
ㄴimages
ㄴlabels
ㄴ test
ㄴimages
ㄴlabels
ㄴ dataset.yaml이런 폴더 구조를 갖춰야 정상적으로 실행된다.
그런데 데이터셋이 이런 구조가 아닌 경우가 생각보다 많다.
우리 프로젝트의 데이터셋도
train 폴더만 있거나, train, test만 있고 val이 없거나 해서 전처리가 필요한 상태였다.
그런 경우는 아래의 코드를 이용해 split 해주면 된다.
!pip install split-folders
import splitfolders
os.makedirs("/content/custom_data/", exist_ok=True)
splitfolders.ratio("/content/datasets/m3finalclass-1/train", output="/content/custom_data/", seed=77, ratio=(0.8, 0.1, 0.1))
이외에도 dataset 전처리용 코드가 많으니 수동으로 하지말고 코드로 하자.
#️⃣ 데이터셋 yaml 파일
names:
- airplane
- apple
- backpack
- banana
'''중략'''
nc: 80
train: /content/drive/MyDrive/Capstone_Yolov5/2_Object/dataset_object/train/images
val: /content/drive/MyDrive/Capstone_Yolov5/2_Object/dataset_object/val/images
test: /content/drive/MyDrive/Capstone_Yolov5/2_Object/dataset_object/test/images
#️⃣ YOLOv5 Classification Train (Scene dataset)
◾ 구글코랩, 하드웨어가속기 GPU, 200epoch
# tensorboard open
%load_ext tensorboard
%tensorboard --logdir runs/train-cls



#️⃣ YOLOv5 Object Detection Train (COCO dataset)
◾ [시도1] 구글 코랩, 하드웨어 가속기 GPU, 100epoch


학습은 잘됐으나 mAP@5가 0.136 밖에 되지 않았다.
그런데 코랩으로 돌리면 시간 제한이 있어서 100epoch이상 train하는 것은 무리였다.
◾ [시도2] 텐센트 가상머신, Teslor T4 GPU, 300epoch

이렇게 정말 지옥같던 환경설정을 마치고 새벽에 겨우 잠을 자고 일어났는데...!
갑자기 다음날부터 인스턴스가 ssh접속이 안됐다!! 콘솔도 ssh연결도 안됐다!!

login via VNC만 가능하길래 접속해서 수많은 해결법을 도전했지만 실패했고 결국 새로운 인스턴스를 할당받았다.
그런데 예전 인스턴스에는 python3.8 에 아래처럼 설정했었는데
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
새로운 인스턴스는 python3.10에 nividia driver, cuda도 설치되지 않은 상태라 다시 한번 환경설정을 해야했다...
◾ [결론]
그러던 도중 ‼️ 새로운 데이터셋으로 fine-tuning하는 것이 필요없다는 것을 깨달았다 ‼️
우리가 원하는 게 COCO dataset 처럼 다양한 클래스의 object를 detect하는거라
COCO dataset의 일부를 이용해 train중이였었다.
(gpu달린 데스크탑이 없어서 데이터셋을 조금만 가져와서 train해보는 중이었다)
그런데 이미 YOLOv5 공식깃허브에서
COCO dataset 전체로 300epoch train시킨
checkpoint가 모델종류별로 4개나 제공하고 있었고
심지어 그 사실을 예전부터 알고 있었다...
해당 checkpoint들은 pre-trained weight로 두고 그 위에 "fine-tuning을 해야만 한다"고 잘못 생각하고 있었다.
우리 상황에서는 fine-tuning 필요없이 pre-trained weight만 써도 됐는데 말이다.
그래서 결국 pre-trained weight인 yolov5s.pt를 이용하기로했다.





#️⃣ YOLOv5 개념
◾ P, R
P : Precision
R : Recall
매우 다른 두 metric는 둘이 반대의 경향을 가진다.
(Precision이 높으면 Recall이 낮은 경향)
Precision-Recall graph (PR 곡선)을 그리고
해당 곡선의 아래 영역 넓이가 Average Precision (AP).
◾ mAP
mean Average Precision
강아지 class의 AP가 0.74
고양이 class의 AP가 0.533일때
mAP는 모든 class의 AP의 평균인 0.6365
◾ s m l x



당연하게도 모델이 복잡해질수록(s<m<l<x) mAP가 올라가지만 그만큼 속도는 느려진다.

#️⃣ 코드 공개
scene classification에서는 top5i 중에서 prob(probability 확률)이 threshold 이상인 경우만 tag로 넘겨주었고, (우리는 threshold 를 0.5로 두었다)
classification 에서는 detect된 class명을 tag로 넘겨주었다.
yolov5 개발 부분은,
우리 서비스에 맞게 작성하는 코드 부분 (아래 python 파일 3개) 보다는
dataset을 선정하고, dataset 전처리하고, train하는게 주를 이뤘다.
코드에 대한 설명은 코드내부의 docstring과 깃허브의 readme 참조 부탁드립니다.
github 링크 : https://github.com/JeongHyoYeon/Capstone-CV-YOLOv5

'GRADUATION PROJECT > 졸업프로젝트 제출물' 카테고리의 다른 글
| [2022-2 졸업프로젝트] ComputerVision + AI (3) | 2022.11.18 |
|---|
