
yeon_vision_
[2022-2 졸업프로젝트] ComputerVision + AI 본문
개요
- 졸업 프로젝트 소개
- 졸업 프로젝트 주제 : Shoe-ting #Shoe #Size #Style
- UI 디자인
- 포스터 초안
- #Size [Computer Vision]
- 구현 아이디어
- 사진만으로 길이 측정 어떻게?
- A4? 동전?
- image segmentation? object detection?
- 구현 아이디어
-
- Contour detect
- C++ 코드
- 시행착오를 통한 threshold hyperparamete 결정
- Image Segmentation
- 이미지 resize
- adaptive_thresholding.cpp
- k_mean.cpp
- object Detection
- object detection 어떻게?
- 실제 구현 코드 & 결과 정리
- 기타 논의 사항
- Contour detect
- #Style [AI]
- 구현 아이디어
- 구글링의 지옥
- 딥러닝모델1 : fashion 2 text
- 딥러닝모델2: recommendation system architecture
- 마무리말
쓰다보니 너무 길어져서 일단은 글1개에 몰아넣었으나 나중엔 글 3개 정도로 분할할 예정이다...ㅎㅎ
💡졸업 프로젝트 소개
"캡스톤 디자인과 창업프로젝트" 수업으로
2022년 09월부터 2023년 6월까지 2학기에 걸쳐서 진행하는 졸업프로젝트이다.
💡졸업 프로젝트 주제 : Shoe-ting #Shoe #Size #Style
프로젝트 요약
#Shoe 프로젝트명 ‘Shoe-ting' 은 '신발(shoe)’과 ‘소개팅(meeting)'의 합성어로 사이즈와 스타일 방면에서 딱 맞는 신발을 이용자들에게 소개한다는 의미를 가진다.
#Size 사용자가 발 사진을 촬영하면 computer vision 기술을 이용해 사용자의 발 사이즈(발길이, 발볼)를 측정하고 사용자가 선택한 신발의 사이즈별 수치와 비교해 맞는 사이즈를 찾아준다.
#Style 사용자가 업로드한 자신의 전신 사진을 AI로 분석해 해당 스타일과 어울리는 신발을 추천해준다.
프로젝트 필요성
다음과 같은 사람들에게 ‘Shoe-ting'이 유용하게 쓰일 것이라고 생각한다.
1. 온라인으로 신발을 구매할 때 사이즈 고민을 하는 사람들
2. 패션에 관심이 많아 좋아하는 스타일에 어울리는 신발을 모아보고 싶은 사람들
3. 패션을 잘 몰라 자신의 스타일에 잘 어울리는 신발을 모르겠는 사람들
서비스 차별성
Shoe-ting(슈팅) = 온라인 쇼핑 플랫폼 + 사이즈 추천 서비스 + 스타일 추천 서비스
신발을 온라인으로 쇼핑할 때 불편한 점들을 해결하는 서비스가 개별적으로는 존재하지만 통합된 서비스는 존재하지 않는다. Shoe-ting은 사용자 사진으로 사이즈와 스타일을 분석해 신발을 추천하기에 사용자는 다양한 브랜드의 신발을 추천 받고 한 곳에서 쇼핑할 수 있다.
개발 아키텍처

팀원소개 + 맡은 부분
우리팀은 front-end 1명, back-end 1명, Computer Vision + AI 1명으로 총 3명으로 구성되어있다.
그 중에서 나는 Computer Vision + AI 부분을 맡았다.
💡UI 디자인
팀원들과 함께 UI를 디자인했다. 이미 수차례 수정을 거쳤는데 더 수정할게 생겨서 수정할 예정이다.
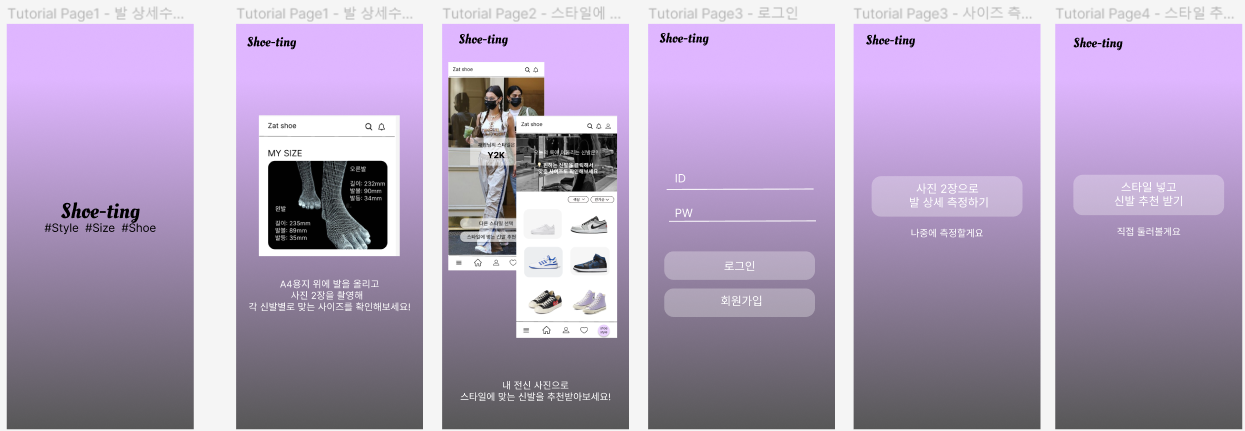



💡포스터 초안

💡#Size [Computer Vision]
우선 input이 발사진 or 신발사진일때
사진을 computer vision 기술으로 분석해서
발 또는 신발의 실제 길이를 분석하는 기술에 대해 공부했다.
📌구현 아이디어
😶 사진만으로 길이 측정 어떻게?
실제 발은 3D인데 사진을 찍으면 2D가 되면서
dimension이 사라지며 길이 정보가 파괴되어 사진만으로는 길이를 알 수 없다.
그렇다면 어떻게 2D 이미지만 가지고 실제 길이를 측정할 수 있을까?
크게 두가지 방법을 찾았다.
방법1) 카메라를 움직여서 측정한다.
image registration (alignment) 기술을 이용한다.
alignment란, (1) 하나의 물체를 여러각도에서 여러장을 찍거나 (2) 한각도에서 시간달리 여러장을 찍고 여러사진에서 물체를 대응하는 것이다.

이런 image alignment기술을 이용해 거리정보를 추출할 수 있다.
아래 그림처럼 기차를 타고가면서 사진을 찍는다고 생각하자.
t1시점에서 사진을 찍고 t2시점에서 사진을 찍는다.
그리고 두 사진을 alignment한다.
가까이 있는 나무의 위치인 파란점은 많이 움직이고,
멀리 있는 산의 위치인 빨간점은 적게 움직인 것을 확인할 수 있다.

즉, 멀리 있는 산보다 가까이 있는 나무가 더 빨리 움직이는 것으로 느끼는데
이를 역으로 이용해 움직임의 빠르기로 얼마나 먼지 길이를 측정할 수 있다.
즉 움직임의 빠르기를 거리정보로 환산할 수 있다.
이를 이용한 대표적인 어플로는 '아이폰 줄자 어플'을 생각해볼 수 있다.
그런데 이 기술을 이용한 어플을 직접 사용해 보니까 생각보다 오차가 심했다. (발이 신체의 일부라서 촬영각도가 어려움...)
거리가 긴 도로의 길이나 건물의 길이를 측정할때는 몇 cm 정도의 오차는 허용하고 이 방법을 이용하는 것이 좋겠지만
길어야 30cm정도인 발을 측정하는 것이므로 몇cm의 오차를 허용해서는 안됐다...
그래서 이 방법은 쿨하게 패스...
방법2) 규격이 정해진 물체(A4용지, 동전, 자) 등을 같이 촬영해서 비교한다. [내가 선택한 방법]
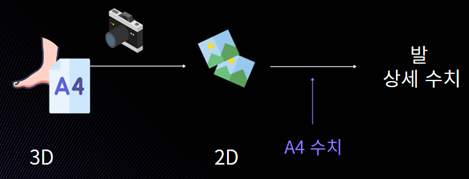

사용자가 A4용지위에 발을 올리고 사진을 찍으면
이미 알고 있는 A4의 수치와 비교해 발 상세 수치를 측정할 수 있다.
사진에서 규격화된 물체가 어딨는지 인식하고
크기를 측정하고자 하는 물체가 어디있는지 인식한다.
그 다음 두 물체의 pixel비율을 비교하면
측정하고자하는 물체의 크기를 측정할 수 있다.
이 방법은 카메라만 수직으로 잘 설정되어있으면 mm 단위까지의 정확성을 제공한다.
따라서
1) 사용자의 사진 입력
2) A4영역 찾고 수평 조정해서 직사각형으로 만들기 (<- 카메라 각도따라 A4용지가 수평이 안맞게 촬영될 수도 있으니 이를 보정하는 것)
3) 발영역을 찾고 A4의 수치와 비교해서 발 수치 측정.
이런 식으로 진행하려고 한다.
😶 A4? 동전?
A4사이즈는 297 x 210mm로 규격화되어있으므로
처음에는 발 사이즈는 보통 220~290으로 잡으면 22cm~29cm정도이므로 A4로 하면 딱이라고 생각했다.
근데 A4위에 발을 두고 찍으면 각도상 발 뒷꿈치에 A4가 가려져서 정확성이 떨어질 수도 있다는 생각이 들었다.
그렇다면 발 옆에 동전을 두고 해도 괜찮을 듯하다!
이건 해보면서 수정하자!
😶 image segmentation? object detection?
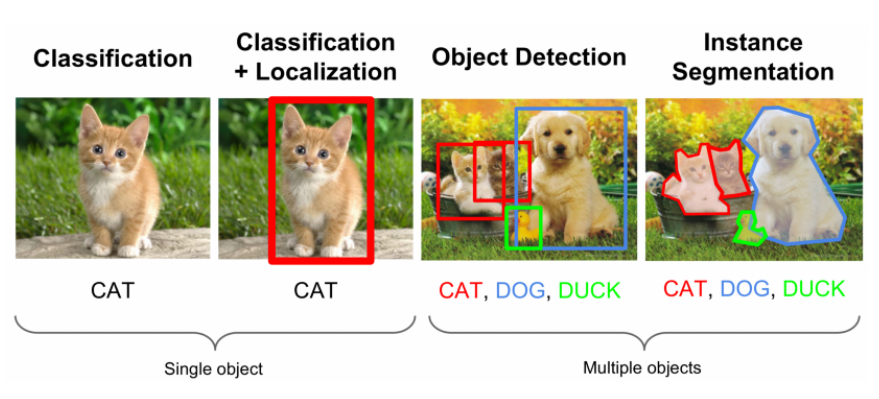
1) image segmentation : [발바닥 모양]과 [신발바닥 모양]의 비교를 시각화해주려했었음.
특징: 정확한 발모양, but 오래걸림.

처음에 프로젝트 타겟을 중년층을 타겟으로 '정확하게' 신발사이즈를 비교해주는 것으로 했을때는,
발사진을 픽셀마다 돌면서 image segmentation해서 정확한 발모양을 따고
신발사진도 image segmentation을 해서 정확한 밑창모양을 따고
그 둘을 정확하게 비교해줄 생각이었다.
그래서 image segmentation부분도 열심히 공부하였는데
프로젝트 타겟이 변하면서 약간 무용지물쓰..가 되어 슬프다... 그래도 공부한거니까^^...
(수정) object detection없이 image segmentation한 결과에 box를 쳐서 진행할 것 같기도하다... 두 방법 다 좀 더 도전해봐야겠다.
2) object detection : 발바닥모양대신, 발에 박스쳐서 길이만 측정. 신발도 마찬가지.
특징: 발에 딱 맞는 박스를 쳐서 길이측정. segmentation보단 빠르고 주제에 알맞음.

변경된 프로젝트 주제는
청년층을 타겟으로, 정확성 중심 대신 빠르고 간편한 길이 측정+스타일 추천 에 중점을 둔다.
그래서 발모양, 신발바닥모양을 알 필요없이 발에 딱 맞는 박스를 쳐서 길이만 측정하면된다.
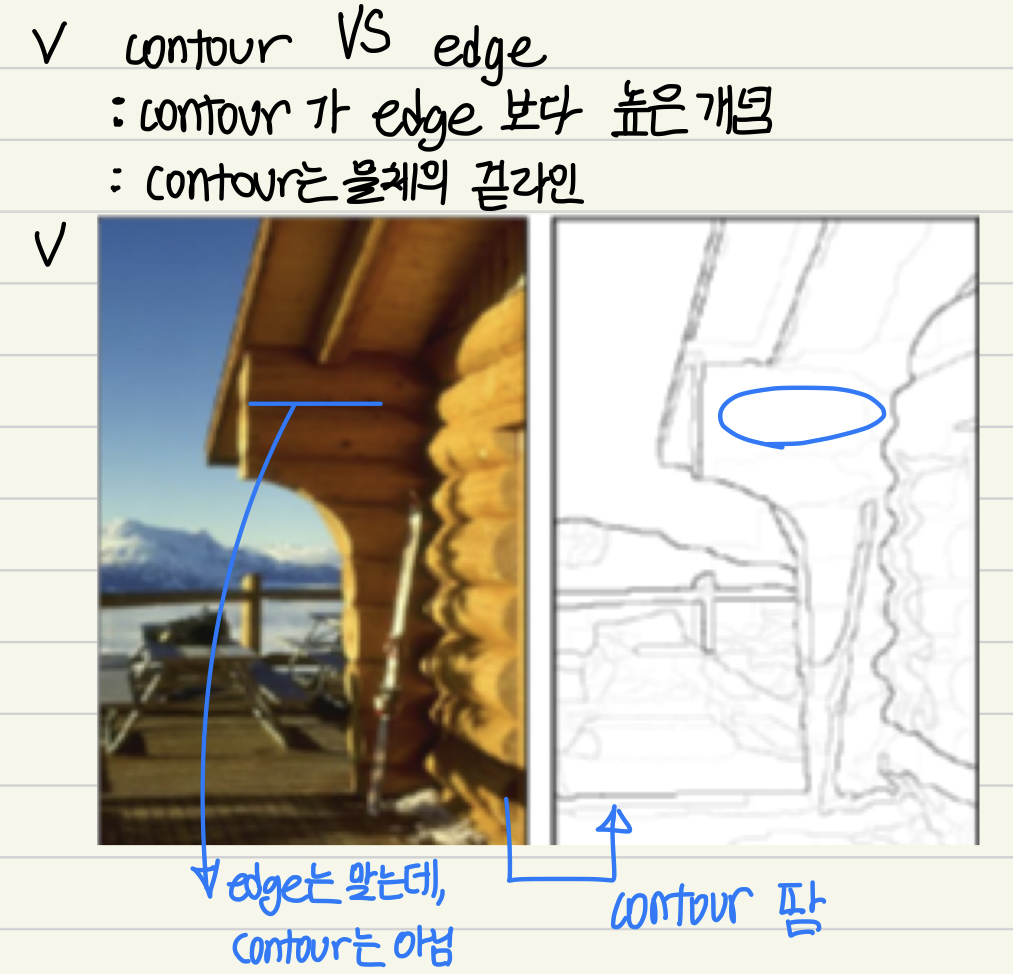
📌Contour detect
😶 Contour VS Edge
😶 C++ 코드
/*canny edge detector*/
#include <opencv2/opencv.hpp>
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace cv;
int main() {
Mat input = imread("test7.jpg", CV_LOAD_IMAGE_COLOR);
Mat input_gray;
// check for validation
if (!input.data) {
printf("Could not open\n");
return -1;
}
cvtColor(input, input_gray, CV_RGB2GRAY); // convert RGB to Grayscale
// input_gray.convertTo(input_gray, CV_64F, 1.0 / 255); // 8-bit unsigned char -> 64-bit floating point
Mat img_edge;
//Fill the code using 'Canny' in OpenCV.
//Canny(input_gray, img_edge, 100, 150); //(넣는 이미지, 결과 이미지, threshold1, threshold2)
Canny(input_gray, img_edge, 70, 120);
float resize_ratio = 0.1;
namedWindow("Grayscale", WINDOW_NORMAL);
resizeWindow("Grayscale", input.cols * resize_ratio, input.rows * resize_ratio); //원본비율 유지한채 사이즈 조절
imshow("Grayscale", input_gray);
namedWindow("Canny", WINDOW_NORMAL);
resizeWindow("Canny", input.cols * resize_ratio, input.rows * resize_ratio); //원본비율 유지한채 사이즈 조절
imshow("Canny", img_edge);
waitKey(0);
return 0;
}😶 시행착오를 통한 threshold hyperparameter 결정 (threshold1, threshold2) = (70, 120)



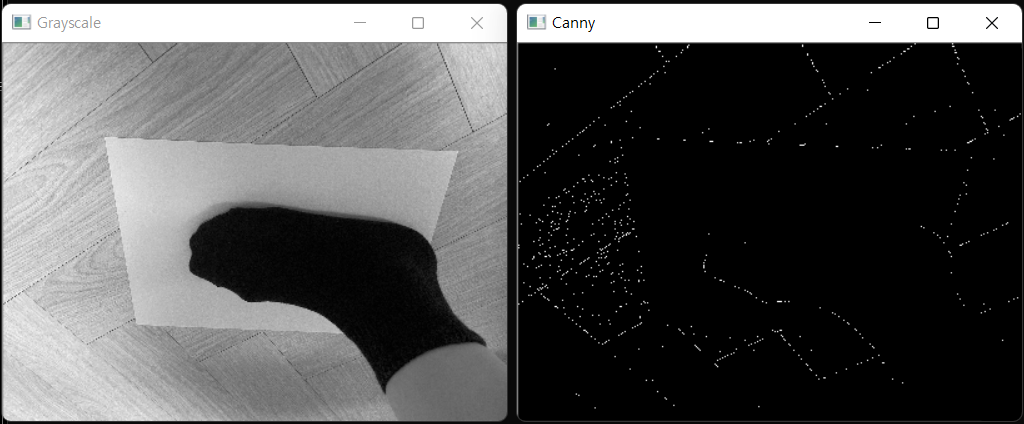
📌Image Segmentation
😶이미지 resize
핸드폰으로 촬영한 이미지를 그대로 넣고 코드를 실행했더니 이미지가 너무 커서 노트북화면을 벗어나버리는 문제가 발생했다. 그래서 사이즈를 줄였는데... 고민할 점이 2가지 있었다.
1) 이미지 자체를 resize? 아니면 보여주는 창만 resize?
정확성 문제, 창만 resize하는게 좋음
이미지 자체를 줄일때는 픽셀제거하니까 그렇다쳐도,
이미지 자체를 늘릴때 interpolation(보간법)으로 픽셀을 채워넣어야하니까 사이즈 측정시 오차가 생길까봐 걱정됐다.
내부적으로는 계산할때 원본 그대로 계산하고 외부적으로 창을 통해 보여줄때만 사이즈 조절해서 보여주는 것이 좋다고 생각했다.
시간문제, 이미지 자체를 resize하는게 좋음
근데 또 연산 시간을 줄이려면,
각 픽셀마다 for문으로 돌면서 계산하고,
size를 조정한다해도 비율은 안달라니지니까 시간을 줄이려면 이미지자체를 resize하는게 좋다는 생각도 들었다...
일단 창을 resize했는데 나중에 바꿔도 좋을듯.
2) 크기측정이 중요하므로, 가로세로 비율 고정한 채로 resize필요!
가로세로 비율 고정안하면 생기는 문제...
// namedWindow("Grayscale", WINDOW_AUTOSIZE); //원본 크기 유지한 창. 창 크기 조절 불가.
namedWindow("Grayscale", WINDOW_NORMAL); //크기 조정 가능한 일반 창.
resizeWindow("Grayscale", 500, 500); //가로 세로 사이즈 조절 가능.
imshow("Grayscale", input_gray); //해당 창을 보여주기.
float resize_ratio = 0.1;
namedWindow("Grayscale", WINDOW_NORMAL);
//원본비율 유지한채 사이즈 조절 (원래의 가로, 세로에 resize_ratio를 곱해서!)
resizeWindow("Grayscale", input.cols * resize_ratio, input.rows * resize_ratio);
imshow("Grayscale", input_gray);
😶 adaptive_thresholding.cpp
/* adaptive thresholing */
//image segmentation : threshold/ adaptive thresholing/ uniform mean filter이용가능.
#include <iostream>
#include <opencv2/opencv.hpp>
#define IM_TYPE CV_8UC3
using namespace cv;
// Image Type
// "G" for GrayScale Image, "C" for Color Image
#if (IM_TYPE == CV_8UC3)
typedef uchar G;
typedef cv::Vec3b C;
#elif (IM_TYPE == CV_16SC3)
typedef short G;
typedef Vec3s C;
#elif (IM_TYPE == CV_32SC3)
typedef int G;
typedef Vec3i C;
#elif (IM_TYPE == CV_32FC3)
typedef float G;
typedef Vec3f C;
#elif (IM_TYPE == CV_64FC3)
typedef double G;
typedef Vec3d C;
#endif
Mat adaptive_thres(const Mat input, int n, float b);
int main() {
Mat input = imread("test7.jpg", CV_LOAD_IMAGE_COLOR);
Mat input_gray;
Mat output;
cvtColor(input, input_gray, CV_RGB2GRAY); // Converting image to gray
if (!input.data)
{
std::cout << "Could not open" << std::endl;
return -1;
}
float resize_ratio = 0.1;
namedWindow("Grayscale", WINDOW_NORMAL);
resizeWindow("Grayscale", input.cols * resize_ratio, input.rows * resize_ratio); //원본비율 유지한채 사이즈 조절
imshow("Grayscale", input_gray);
output = adaptive_thres(input_gray, 2, 0.9); //Fix with uniform mean filtering with zero paddle
namedWindow("Adaptive_threshold", WINDOW_NORMAL);
resizeWindow("Adaptive_threshold", input.cols * resize_ratio, input.rows * resize_ratio);
imshow("Adaptive_threshold", output);
waitKey(0);
return 0;
}
Mat adaptive_thres(const Mat input, int n, float bnumber) {
Mat kernel;
int row = input.rows;
int col = input.cols;
int kernel_size = (2 * n + 1);
//(uniform mean filtering) Initialiazing Kernel Matrix
kernel = Mat::ones(kernel_size, kernel_size, CV_32F) / (float)(kernel_size * kernel_size);
float kernelvalue = kernel.at<float>(0, 0); // To simplify, as the filter is uniform. All elements of the kernel value are same.
Mat output = Mat::zeros(row, col, input.type());
for (int i = 0; i < row; i++) { //for each pixel in the output
for (int j = 0; j < col; j++) {
/*STEP1. finds the mean intensity using uniform mean filtering with zero paddle border process.*/
// m(i,j) = (i,j)에서 uniform mean filter와 convolution
float sum1 = 0.0;
for (int a = -n; a <= n; a++) { // for each kernel window
for (int b = -n; b <= n; b++) {
if ((i + a <= row - 1) && (i + a >= 0) && (j + b <= col - 1) && (j + b >= 0)) { //if the pixel is not a border pixel
sum1 += kernelvalue * (float)(input.at<G>(i + a, j + b));
}
}
}
// T(i,j) = b * m(i,j)
float temp = bnumber * (G)sum1;
/*STEP2. find output using adaptive thresholding*/
// g(i,j) = { if( I(i,j) > T(i,j) 255, else 0}
// Fill code that makes output image's pixel intensity to 255 if the intensity of the input image is bigger than the temp value, else 0.
if (input.at<G>(i, j) > temp)
output.at<G>(i, j) = 255;
else
output.at<G>(i, j) = 0;
}
}
return output;
}😶 k_mean.cpp


📌Object detection
😶object detection 어떻게?
[아이디어1] contour 뽑기 > 제일 위쪽 부분, 아래 부분, 왼쪽부분, 오른쪽부분으로 image 박스 찾기
- 전처리
- (이미지 크기 조정) (<- 시간줄일 수 있을 것 같아서)
- (grayscale로 바꾸기) (<- 시간줄일 수 있을 것 같아서)
- contour detect
- A4용지 찾기
- A4용지 기준으로 상하좌우 이미지 조정 (transform해서 직사각형 만들기)
- 발 박스 찾기
- 발 길이 측정 (A4사이즈와 비교)
[아이디어2] YOLO모델로 image 박스 찾기 > 해당 사이즈 찾기
- 전처리
- (이미지 크기 조정) (<- 시간줄일 수 있을 것 같아서)
- (grayscale로 바꾸기) (<- 시간줄일 수 있을 것 같아서)
- YOLO모델로 A4용지 찾기
- A4용지 기준으로 상하좌우 이미지 조정 (transform해서 직사각형 만들기)
- YOLO모델로 발 박스 찾기
- 발 길이 측정 (A4사이즈와 비교)
📌실제 구현 코드 [아이디어1로 구현함]
예전에 AI모델을 이용한 웹사이트를 만들었을때를 생각해보면
"구글코랩이 온실이라면 로컬은 야생이다." ㅎㅎㅎ
그래서 일단 구글코랩에서 코드에 문제가 없나 테스트를 마치고
나중에 로컬에서 여러 환경설정이랑 더 진행하려한다!!

https://colab.research.google.com/drive/1OuKVDCB_-kOYgCmJ9BzjodiRQZs551VK#scrollTo=7Lr0C3lvX-hH
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
문제점1.
일단 가장 왼쪽에 선택된 bounding box가 referenced object라고 구현해둠.
그래서 제일 왼쪽에 동전을 뒀는데도 이상한 것들을 제일 왼쪽이라고 인식해버려서 잘 안됨.
> 나중엔 A4나 동전을 직접 찾아서 그게 referenced object라고 판단할 수 있게 구현해야함. 아님 A4길이를 찾거나. 그걸 아마 YOLO object detection으로 해야할 것 같음.
문제점2.
바닥이 너무 어지러우면 잘 안됨
일단 A4깔고 A4부분만 crop해서 해봤음.
> 나중엔 알아서 A4부분 크롭하게해야할듯.
문제점3. 발의 한계... 발은 사람 다리에 붙어있다...!!
다른 물체는 잘되는데 발은 특징점이 없어서 잘 안됨.
발이랑 발목이랑 붙어있어서 자꾸 발목까지 측정됨.
사진하나로 발길이 + 발볼 다 측정가능할 줄 알았는데
> 살짝 꺾어서 발 옆부분 보이게 찍어서 발길이 1개.
발목안보이게 발볼부분만 다시 찍어서 발볼길이 1개로 해야 할듯.


시도1. gray로 바꾸기 > gaussian filter로 blur > contour따기 > bounding box쳐서 구하기
잘 안됨... bounding box가 진짜 이상한 곳에 쳐짐...
시도2. gray로 바꾸기 > adaptive thresholding으로 image segmentation을 시각화 > gasussian filter 없이! > contour 따기 > bounding box쳐서 구하기
발영역도 제대로 못찾음... 대강 찾긴함...


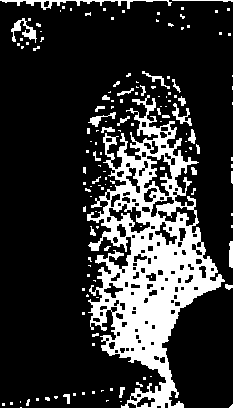


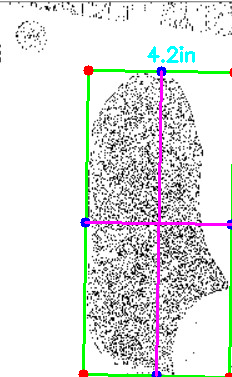
시도3. 대비를 매우 높이고 시도2다시.
오!! 발영역을 정확하게 찾았다!!
(개선점1) 발목까지 인식하니까 발볼길이는 엉망이고, 발길이도 약간 이상하게 잡음.
(개선점2) 여전히 동전쪽을 제일 왼쪽이라고 인식하진 못하는 중





📌기타 논의사항
1. 측정 페이지에서 유저가 이해하기쉽게 가이드라인 구현해야함.
각도 추천도 해주고 설명도 알잘딱깔센으로 잘 설명해줘야함.
2. 마이페이지에서 ‘평소 신는 운동화 사이즈’를 입력하게해서
만약 평소 250신는다고 했는데 측정결과가 220 막 이러면
“너 평소 신는 사이즈랑 많이 다른데 측정잘못된거 같은데 다시 측정할래?" 하고 물어보는 기능 만들자.
💡#Style [AI]
후 일단 핵심기능1인 #Size [computer vision]부분은 어느정도 검증은 마친 것 같다. 방학때 더 해보면 더 많이 발전할 수 있을 것 같다.
그럼 이제 핵심기능2 인 #Styel [AI] 부분이 남았는데... 약간 벌써 스압이...
수많은 노고와 많은 내용들을 글 1개에 몰아넣는게 너무 가독성 떨어지지만 여기서부턴 새로운 이야기이니 리프레쉬하는 마음으로~
📌구현 아이디어
구현 방법1.
사용자 사진으로 캐쥬얼인지 Y2K인지 classification.
그리고 Y2K면 운동화... 이런 식으로 추천
생각할 점: 패션을 Y2K이다, 스포티이다. 라고 정할 수 있는 기준이 애매하다.
구현 방법2.
데이터셋 : 옷 잘 입은 사람들 전신 사진. 신발까지 보이게.
옷사진 크롭. 신발사진크롭. 따로 보관.
사용자 사진 > object detection > 옷사진과 데이터셋안의 사진 비교 > 그 사람의 신발 추천
생각할 점: 옷 잘입은 사람들 중에서 다양한 신발을 신은 사진을 충분한 수로 구하기 힘들 것 같다. + 그 사진을 다 크롭해야되니까 힘들듯...
+ 그 사람이 신은 신발 사진만 보여주면 안되고 그거랑 유사한 우리가 파는 신발의 사진을 보여줘야해서.
이것도 시간이 되면 이 방법도 좋을 것 같다.
구현 방법3. 일단 이걸로 결정!
사용자 사진 > deep learning architecture > 어떤 옷을 입었는지(ex 치마+블라우스 조합이다) 색상 정보 등 옷 정보를 텍스트로 추출 > 맞는 신발 리스트 > 해당 리스트를 deep learning 알고리즘을 이용해 정렬.
원래 밑줄친 부분은 manually 정할려고 했는데, (치마+블라우스 조합이면 메리제인종류, 스니커즈종류, 니하이종류 다 맞는신발 리스트에 넣기 이런식으로)
다른 팀원(정현lee)이 알고리즘을 통해서 스타일의 유사도를 계산해서 유사도가 높은 신발의 리스트를 구하기로 했다.
신발이 어울리는지 안어울리는지는 수학문제처럼 옳고 그름을 판단하기가 힘들어서
"이건 어울린다. 안어울린다. "보다
폭 넓게 이런 신발들이 어울리는데, 딥러닝아키텍쳐를 이용한 추천 정렬로, "이러한 추천기준에 의해서 이런 먼저나오는 신발들을 더 추천할게~"라고 하는 것이 맞다는 생각이 들어서 구현방법3을 이용하기로 했다.
📌구글링의 지옥
AI를 공부하기위한 과제들은 많이 해봤어도
실제로 내가 필요한 AI 모델을 fine tuning하기위한
기존 모델을 찾고 데이터셋을 찾는 과정은 실리콘밸리온라인 인턴십에서 한번 밖에 안해봤기에...
이번에도 구글링만 족히 20시간 이상은 했다...
아래 두페이지랑 github에서 꽤 많은 도움을 받았다!
https://paperswithcode.com/datasets
Papers with Code - Machine Learning Datasets
7350 datasets • 84281 papers with code.
paperswithcode.com
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
📌딥러닝아키텍처1 : Fashion2Text
앞으로 input이 옷사진이고 output이 어떤 옷을 입었는지에 대한 text정보를 추출하는 딥러닝 아키텍쳐를
"Fashion2Text" 아키텍처라고 부르겠다.
이 아키텍처에서는 dataset은 유명한 것은 FashionMNIST, DeepFashion1, DeepFashion2, 그외의 수많은 데이터셋을 서칭했는데 아직 어느것이 좋을지는 잘 모르겠다.
그러나 FashionMNIST는 gray이미지라서 안쓸 것 같다.
fashion recommender 코드를 찾았는데 예전코드라 에러가 많고 우리가 사용하고자하는 것과 다른 점이 많아
수정 중이다.
근데 일단 dataset도 공개를 안해줬기에 이 코드를 그대로 쓸 일은 없을 것 같긴한데
전신사진이미지를 가지고 그 사진에서 입은 옷을 설명하는 text를 찾을때도
VGG16을 이용해서 할 수 있다는 아이디어를 엿볼 수 있어 해당 코드를 리팩토링하며 공부 중이다.
https://colab.research.google.com/drive/1KjJ3HNeUIOUjsjQF_Fagi0xHsaT7pX8g?usp=sharing
FashionNet._testipynb
Colaboratory notebook
colab.research.google.com


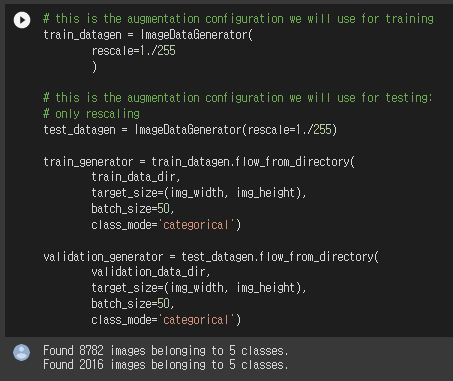
... 중간 생략
vgg16 network 구현.
def build_vgg16(framework='tf'):
if framework == 'th':
# build the VGG16 network in Theano weight ordering mode
backend.set_image_dim_ordering('th')
else:
# build the VGG16 network in Tensorflow weight ordering mode
backend.set_image_dim_ordering('tf')
model = Sequential()
if framework == 'th':
model.add(ZeroPadding2D((1, 1), input_shape=(3, img_width, img_height)))
else:
model.add(ZeroPadding2D((1, 1), input_shape=(img_width, img_height, 3)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
return model
weights_path = 'vgg16_weights.h5'
th_model = build_vgg16('th')
assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(th_model.layers):
# we don't look at the last (fully-connected) layers in the savefile
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
th_model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
tf_model = build_vgg16('tf')
for th_layer, tf_layer in zip(th_model.layers, tf_model.layers):
if th_layer.__class__.__name__ == 'Convolution2D':
kernel, bias = th_layer.get_weights()
kernel = np.transpose(kernel, (2, 3, 1, 0))
tf_layer.set_weights([kernel, bias])
else:
tf_layer.set_weights(tf_layer.get_weights())
top_model = Sequential()
print (Flatten(input_shape=tf_model.output_shape[1:]))
top_model.add(Flatten(input_shape=tf_model.output_shape[1:]))
top_model.add(Dense(512, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
print (tf_model.summary())
print(top_model.summary())


📌딥러닝아키텍처2 : Recommendation System Architecture
유튜브에서도 나에게 가장 추천하는 영상을 가장 위에 띄워주듯
우리는 일단 내 스타일에 어울릴 것 같은 신발들을 다 보여주되
그 신발들을 추천시스템아키텍쳐를 이용해서 어떤 기준에 의해 정렬해서 보여줄려고 한다!

input이 신발의 list와 추천정렬에 필요한 정보들일때
output이 정렬된 신발list인 deep learning architecture를 구현해야한다.
1. candidate generation : using collaborative filtering ( deep nueral network )
2. scoring
3. re-ranking
해당 부분의 아키텍쳐는 아직 공부 중이다.
💡마무리
정리하자면
내가 맡은 부분은 발사진으로 발길이를 측정하고,
전신사진으로 사용자의 스타일에 맞는 신발을 추천해주는 기능인데
발사진은 여러 전처리를 거친 후 bounding box를 그려서 기준물체랑 크기를 비교해 측정할 것이고,
전신사진은 1. 사진으로 입은 옷을 텍스트로 변환 2. 알고리즘으로 어울리는 신발 리스트 추출 3. 해당 리스트를 추천시스템을 이용해 정렬할 예정이다.
#Size부분은 코드 진행은 많이 됐으나 개선이 더 필요하고
#Styel부분도 많은 데이터셋과 참고자료들을 찾아 스크랩하고 정리해두었으나 실 구현을 위해서는 방학때 열공해야할 것 같다.
역시 처음 구현할때는 투자하는 시간에 비해서 성과가 잘 안 드러나는 것 같기도하고ㅜ0ㅜ
기술검증은 다 되었으니 이제 내가 더 공부하고 내가 코드를 잘 짜는 일만 남았다! ㅎㅎㅎ
할 수 이따...! 화이팅!
마지막으로...
같이 할 수 있는 일은 같이 열심히 하고
각자 맡은 부분도 열심히 공부하고 구현하는 팀원들 사랑훼..
풋마이스니커즈온 팀 화이팅❤️

'GRADUATION PROJECT > 졸업프로젝트 제출물' 카테고리의 다른 글
| [2023-1 졸업프로젝트] FaceRecognition & YOLOv5 (0) | 2023.05.14 |
|---|
